One of the most important characteristics of the modern data platform is the self-service capability. In order to unlock this capability, one must be sure that all the groundwork has been done perfectly well, so that semi-casual data users from various functions and departments can have reliable and high quality data available to work with.
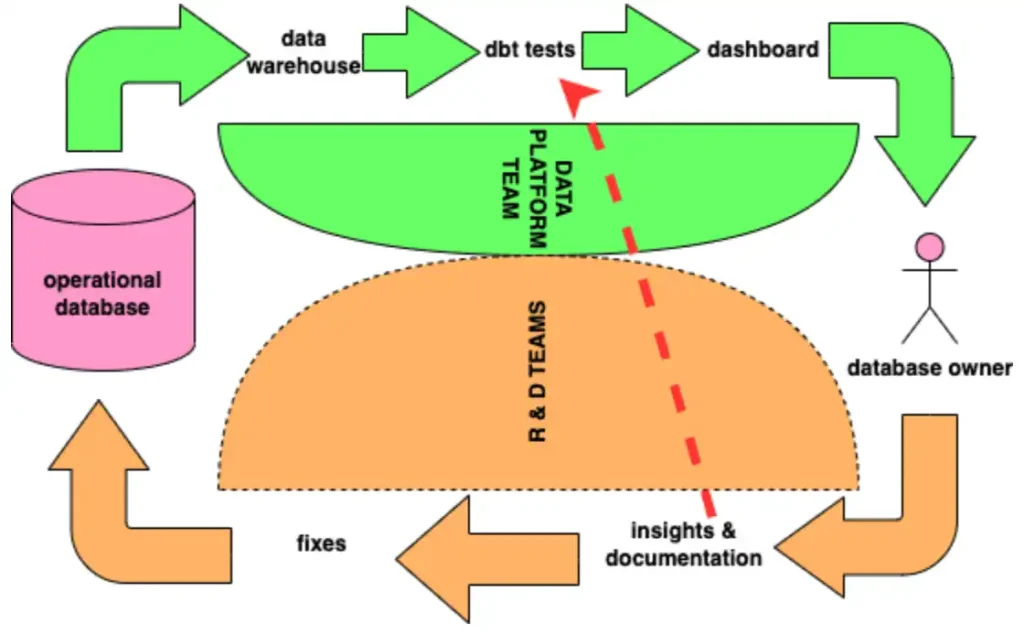
Today’s enterprise level data architecture contains two somewhat different areas where one is devoted for operational data and other to analytical data. These two areas have their own certain place also in the enterprise structure where the first one is managed by various business units and corresponding R & D teams and second one is managed by head of data & analytics. Connecting links between these two data areas are some sort of ETL (extract – transform – load) solutions that are fragile by their nature. This means that any unexpected change in the operational database can cause a failure upstream. These failures can sometimes be costly for the organization and are comparable with driving a bus in the dark without headlights. Therefore it is important that those two data fields are working in conjunction and have a well established working relationship.
With one of our clients we have a team of full stack data developers who can build ETL jobs as well as model data and build core reports. This operation is supported by the team of data scientists who also model data and build more complex solutions according to the business needs. For both of these teams it is important that the data quality is high, the data points are well defined and tables contain all the essential attributes for analytics. One way to achieve it is first to have data quality standards in place and data quality dimensions such as accuracy, completeness, conformity, consistency, coverage, timeliness and uniqueness are agreed across the R&D teams who own the operational databases. Key aspect here is that the R&D teams not only own the operational databases but also the data kept in these databases. The responsibility of the Data Platform team is to build a monitoring system that would help R&D teams to easily identify discrepancies in data quality and fix them.
With the help of an open-source framework called data build tool, we are able to build and define a second layer of constraints to the source tables and columns. While the operational databases resolve constraints such as uniqueness and not null, then on the data warehouse side, where all operational data gets loaded into, we are able to look at the columns on the value level. A simple example of this would be an address table containing a city column. There might already be some length constraints on that column but cities can be spelled/misspelled in different ways, causing data inconsistencies for analysts trying to group data based on those fields.
This is the starting point of communication and support between the Data Platform team and the R&D teams owning the source data. Our tools provide the resources to scan through large amounts of data that might take hours on operational databases. We provide intel on the quality of the data within a table, whether it be misspelled cities, empty strings, incorrect values, and notify the source owners of such cases. The goal would be to push the cleaning of data as close to the source as possible and provide database health check dashboards for the teams, keeping the process organized.
Some more difficult challenges lay in cases where the data is split between the database and the source code. For example enums with custom properties might be reflected in tables that are using them, but the enum context itself is only defined in the code. To solve these data completeness issues, the Data Platform team is again providing support to the R&D teams so that the missing context is identified and documented.
In order to keep the high standards of the data quality, cooperation between the data platform team and operational database owners is essential. No less important is the common understanding between the developers, team leads and product owners about the value of quality data for the business reporting so the fixes of deviances can be addressed and prioritized promptly. One way to achieve this is the continuous feedback loop (Figure 1) via dbt tests which are improved according to the new findings. This is one way to tackle the problem and suitable for our use case but definitely not the only way.