Presented in Data Innovation Summit 11th of May 2023
There have been numerous articles written about how the modern data platform should look and what could be the adequate choices, to build a scalable, reliable and governed platform. Various choices can be made according to the size and data intensity level of your organization.
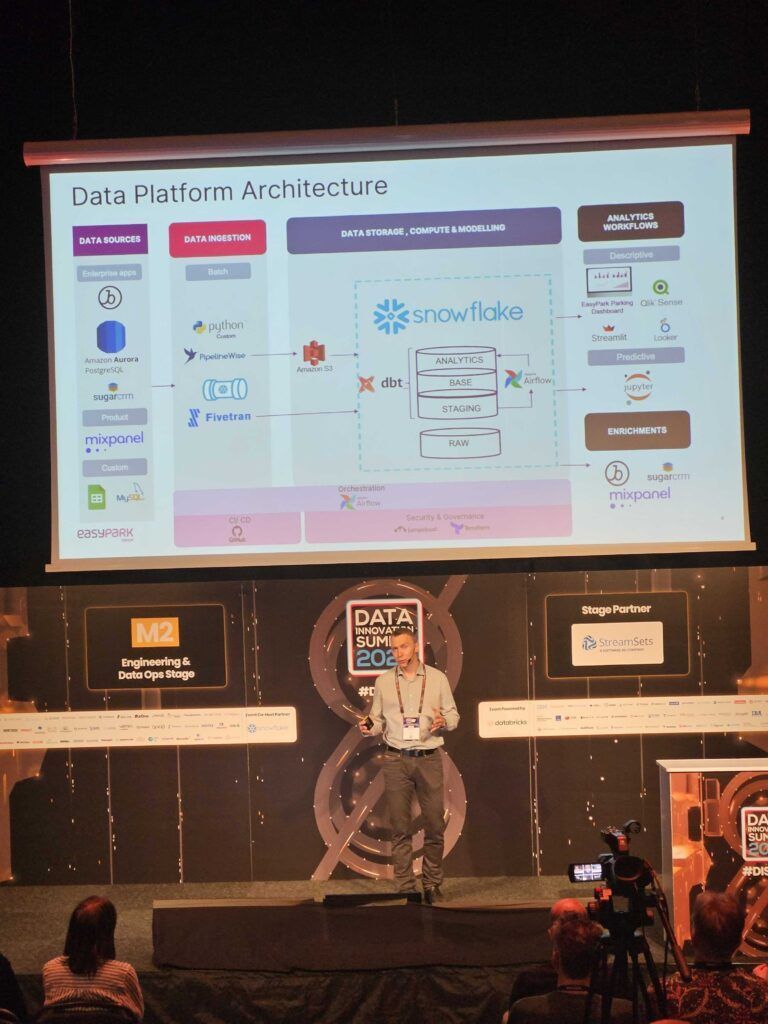
At one of our major projects related to EasyPark Group, we have preemptively followed the path that has become mainstream today. Our central data warehouse is in Snowflake Data Cloud and transformations and modeling are done in the dbt layer. The platform is governed via Terraform scripts and orchestration is handled by Apache Airflow.
For quite a while we have been using singer.io based open source tool PipelineWise or custom python scripts for ETL processes. On one hand, it has been cost effective as we don’t have to spend any money on the essential tools, but on the other hand, these solutions are difficult to scale and require active maintenance. In 2021 Easypark acquired ParkNow Group which meant that the company entered the fast track migration phase. The Data Platform team felt the pressure of stakeholders to deliver faster and more reliably the data from different sources. Increased data volumes in our most critical databases caused problems in our data pipelines as they started to break more often, needing lengthy full historic syncs taking up to 11 – 12 hours. The pipelines were also prone to errors when schema or structure change wasn’t communicated by the product team, causing the sync break and stakeholders to face downtime in analytics. We witnessed a growing amount of maintenance overhead because some specific knowledge was needed on how to manage Kubernetes resources and it was also time consuming to identify errors. Onboarding new people to the data platform needed DevOps skills and was a lengthy procedure.

Rather than just increasing the headcount and adding more people to look after our ETL process, the team started looking for alternative solutions. We had 8 different managed ETL providers under investigation and testing phases. Fivetran stood out for us because it offered multiple methods for ETL that weren’t based on singer.io but seemed more effective. We had tested Fivetran a year ago when we tried to connect our Mixpanel data to Snowflake. Back then we were unsuccessful because Fivetran wasn’t able to deal with historic data sync that contained approximately 60 billion events. However, we decided to give it another try because our new colleagues from the US team were very positive about the way the tool works for them. Of course we also had some concerns that surfaced during that process. For example how Fivetran can effectively support us in two to three different realms (EU, US, UK, Australia) while the main account is in the EU? How secure is it to pass data through the third party service provider? How much load would it put on our operational databases during the replication process? And of course the main question is how much it’s going to cost and how we can justify this expense?
All the concerns we had were alleviated. Fivetran promptly supported us more or less around the clock, even though the main account is in the EU. All the connections to the sources and destinations are SSL (Secure Socket Layer) encrypted by default and they also have transparent customer data retention policy. Different sources have different replication methods available and the ones we have been using on our Aurora Postgres, MS SQL Server and MySQL databases haven’t put any significant load on the operational databases that could affect their performance.
There have been several benefits we have experienced over the last six months by moving over to the managed ETL tool.



